PostgreSQL and typeorm — Intro to persistence
Introduction
This course is designed to help you get into the world of persistence with typeorm and postgres.
By the end you’ll also have a vocabulary for discussing persistence in any application.
This first module is an introduction where we cover many terms and concepts that we’ll use later.
Database course index
This is part of a full course on persistence in postgres with typeorm and sql!
There is a github repo to go with this course. See part 2 for instructions.
- Intro to persistence (you are here)
- Creating a local instance
- Storing data in postgres
- Getting into relations
- Advanced querying
- Transactions
- 9 tips, tricks and common issues
- Database administration glossary
Programs and data
All software programs read data, process it, output the results. We want to use the result of the processing. At the core, this is all software does.
Sometimes the source or destination for data is not “persistent”. An example of a destination for data that is not persistence is the UI screen of an application.
Very often the source or destination of our data is a persistence. Examples of persistence technology for data is a database table, a usb drive or an AWS S3 bucket.

What we will use the data for later later determines a suitable persistence store. In general we call the type of data “Data type(s)” and we call how we will use the data “access pattern(s)”.
Choosing a data store: Data types
The type of data I want to persist will be a factor in what technology I chose. Each datastore is built around specific types of data that it’s good at working with.
There are two main categories you should be aware of — Primitive types and blobs. Using the wrong data store for a type is possible but usually causes lots of issues!

Primitive types
Ultimately everything on a computer is stored as numbers but it’s more useful to think about the next level of abstraction up called “primitive” types.
A primitive type is an abstraction on top of the computer’s numbers so humans can also work with the values without having to convert them from what the computer uses all the time.
Primitive types available in most systems are a string (text), a boolean (1 or 0, true or false) and a number.
Every computer and persistence layer technology has even more specific types of each primitive that they understand very well, and can work with very efficiently with.
e.g. for numbers we have integer and floating point. They are both numbers but when in their specific type they are treated differently in most systems.
Anyone that remembers on of going from 16-bit to 32-bit to 64-bit computing — this was the computers being able to work on newer, larger types of numbers more efficiently.
Examples of primitive type stores: most databases
Blobs
We can see in the diagram above that our furry friends are pictures, computers store pictures using their own number system too.
They are structured collections of numbers that represent the colours, saturation, luminosity etc of each pixel. We obviously can’t read that and imagine the picture.
you have to view the whole thing together and the computer has to interpret the text in a special way to produce the image.
We call things like that bunch of characters “blobs” for “Binary Large OBject”.
The thing to note here is that the giant list of characters is hard for the computer to work with. They have to read the whole thing to understand what it is.
Blobs are not as easy to work with as primitive types. So we treat them distinctly.
Examples of blob stores: your hard drive, amazon s3 buckets
Glossary: structured Vs non-structured data
When working with persistence you’ll likely here structured and unstructured, let’s cover that now.
Structured Data
Structured data has a defined model e.g. a table in a database. It usually uses primitive types and is easily understood by programs.

Consider the example of a structured address above.
A computer can easily verify if an address stored in a structured way is valid because it can review each property of a structured address and validate it against rules.
Unstructured Data
This data has no defined schema or model. Good examples of unstructured data are images and pdfs.
An image with an address on it is unstructured data.
Modern AI techniques aside, a computer can’t easily “see” and interpret this image and read the address.
Humans are incredible at interpreting unstructured data like this image, computers not so much.
semi-structured data
This is data where the format is strictly defined but the contents may not be. JSON is a good example of this kind of data.
We know that JSON can only be objects, booleans, strings and numbers. But we don’t know which of those that a given property is supposed to contain.
{
"street": "some string",
"postcode": 1,
"state": "could be any string we like!"
}Without a schema we have to validate and check every property.
Document databases are often storing this kind of semi-structured data.
They usually accept and store a json document. But they make no guarantee that each document conforms to the same schema.
Choosing a data store: Access patterns
Every program will access data differently and we’ll try to choose a persistence technology to best suit the required access. But what do we mean by access pattern?
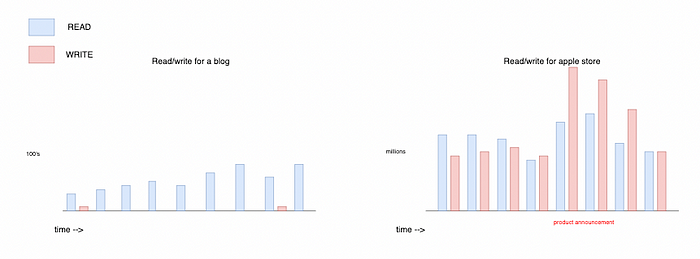
If you think of a typical blog. I might write an article once per month but the article is read 10,000 times per month. So for this application the read/write ratio is heavily skewed towards reading the data.
In this case I wouldn’t need to choose a persistence store that prioritises writing 100,000’s of new blog posts per minute. I could probably use any datastore for this blog really — even a pre rendered html document (string)!
But what if you have an application that processes shopping after a huge marketing campaign like Apples product announcements? The burst in volume of persistence writes for that application must be enormous. For this scenario we would need something that can work the same on bursty loads as well as normal loads.
So you see there is quite a difference. Other common access patterns that we might consider include
- Do you need predictable query performance or is ad-hoc ok?
- Do you know the main queries beforehand or will this be unknown until later? e.g.Will the queries only have one key?
- Is it important that you read the data exactly as written just after you write it? (consistency)
We’ll go into the detail on these later!
Choosing a data store: OLAP vs OLTP
There are two large categories of usage patterns for data stores.
When we’re using a data store to hold the data needed to run our application functions we call it “Online Transaction Processing” (OLTP).
An OLTP database is focused on transactional processing. This is the database we generally use in our consumer applications. We insert, update, select and delete data in the database all the time and we need it to be fast.
Later, when our business needs to analyse what happened in the past to make strategy decisions, that is analytics. They need to transform and explore the data. They might need to combine the data in interesting ways. You don’t know before hand how they will need to manipulate the data to extract what they need.
This type of datastore usage is categorised as “Online Analytics Processing” (OLAP). These databases are focused on answering questions about data. Mix panel and google analytics are examples (this is not strictly true, they are products, but illustrate the difference well).
OLTP databases often feed their data into OLAP databases. OLAP databases likely store much more data than the OLTP database for your application.
There are no specific “OLAP databases” or “OLTP databases”. You can use any datastore for either.
But some databases are better for OLAP than OLTP and vice versa.
Database software examples!
Ok! so let’s talk about some of the databases you’ll likely see and hear about at work!
RDBMS: Postgres DB or SQLite
These are types of relational database management system (RDBMS). Each entity is described by it’s properties which are usually primitive types. We call the entities tables. Entities can have relations to each other.
The entities and properties are usually strictly enforced with a schema that describes intended use of the structure.
CREATE TABLE IF NOT EXISTS myAppSchema.table_name (
idColumn INTEGER PRIMARY KEY,
fullName TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
)If we try to insert an item without an email the RDBMS will protect us. If we try to insert a duplicate email, the RDBMS will protect us. These protections are not free, they cost time to check.
Relational databases usually guarantee consistency, they will guard against writing wrong or bad data. They usually provide fine-grained user access control right in the database.
Relational databases are very common in line-of-business apps. RDBMS are usually quite versatile and are a good place to start for any application.
Some issues with them are that they are often generalist data stores — they’re good at everything but not great at any one thing.
RDBMS are often abused and get used where other datastores are better choices just because they are already running in an organisation’s infrastructure. This gives them a bad reputation.
It can be tricky to map procedural coding structures to relational structures. RDBMS are often used with ORMs which can also be abused by devs. This is covered in detail in later lessons.
AWS RDS, GCP and Azure SQL Database provide managed postgres instances. Sqlite is free and is a fantastic database choice for applications of any kind.
Key value store : Wide column : DynamoDB
A key value store does not usually have a schema like in RDBMS.
A wide column datastore stores entity attributes in “columns”, but every entity does not need to have the same columns.
Key value stores generally don’t support relations between entries. Instead you have to model your data to be fully denormalized. The data still has relations, but all the relations are stored together in the same “row”.
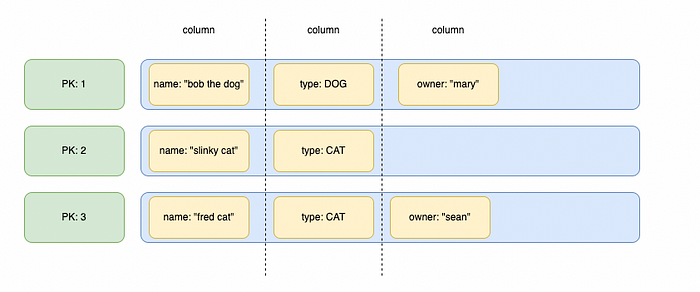
The key-value data retrieval pattern is suitable when you know the key(s) you will use upfront. Or, another way to say that is if you don’t know your access patterns up front then a key-value store might not be the right choice.
Key-value stores have nice properties like easier partitioning for the database management software (because it already implicitly knows your access patterns). They are often automatically replicated and they have some sort of eventual consistency you have to consider because of the availability they offer.
It’s not easy to join these data stores with other datastores, for aggregates and other OLAP uses. Complex querying is difficult with wide-column datastores, at least compared to relational data stores.
AWS DynamoDB and Azure Cosmos are managed examples of wide-column databases.
Key value store : Document store: Mongo
Document stores typically don’t have a schema. Mongo is an exception here, you can enforce a schema if you like. Most people don’t.
A document store is a special case of key-value store where you retrieve an entire document based on a single key.
MongoDb Atlas is an example of a managed document database.
Key value store : cache : Redis
Redis is an in memory key-value datastore. This makes it very suitable for caching data.
Data in a cache like this is considered ephemeral. Items will be removed the storage engine to make way for new items.
An interesting thing about redis is that it also persists the data to disk, providing durability to your data to within a couple of seconds.
Redis provides extremely fast concurrent reads. Easily scaling to 10’s of thousands of reads per second
AWS MemoryDB, AWS Elasticache and Azure Cache for Redis are managed services that will provide you with key-value stores.
Blob store : S3
Blob stores are designed to give you great management of unstructured data. The store itself generally won’t validate the data because it cannot understand the blob contents.
Blob stores provide specific features to help you manage blobs — they will backup your data, limit access to the data, automatically version your data, ttl your data.
They usually provide interfaces for streaming the blob contents or even serving them publicly over http.
Think of how your hdd works except with an http interface!
Summary
Almost every program will have persistence of some kind. Most production apps will have more than one type!
You should have a good idea of the names of stores that are suitable for a given type of data.
Lesson index
Originally published at https://www.darraghoriordan.com.
